How to Build AI Agents That Work in Production: The Complete Guide (2026)
Most guides on how to build AI agents stop when the code runs. This one covers the full lifecycle — framework selection, production architecture, observability, LLMOps, and the AI operations discipline that keeps agents healthy after launch.
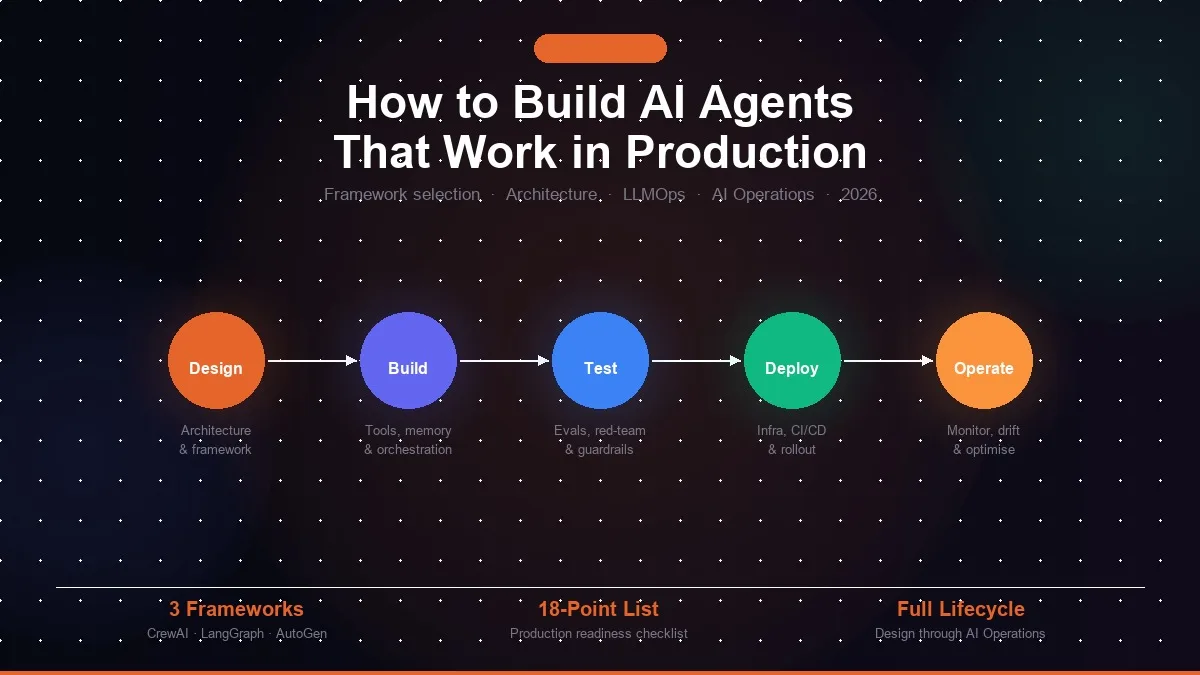
Most guides on how to build AI agents stop the moment the code runs. They show you how to wire an LLM to a tool, produce a successful test case, and call it a day. What they skip is everything that happens next: the production deployment, the degrading retrieval accuracy at week six, the token bill that doubled without warning, the compliance team asking for an audit log you never built, and the quiet performance regression nobody noticed until a user complained. Building AI agents is the easy part. Running them is the discipline most engineering teams have not yet developed.
This guide covers the full lifecycle of an AI agent — from framework selection through production deployment to long-term operations. It is written for engineering teams and technical decision-makers who are serious about shipping AI agents that remain healthy and cost-effective beyond the first 90 days. If you have already shipped agents and are dealing with production problems, jump to the AI Operations section and the 18-point go-live checklist.
Kovil AI · AI Operations
We build and operate production AI agents — scoped, deployed, and monitored as a managed service.
The core thesis of this guide: building AI agents is a software engineering problem. Running AI agents in production is an operations engineering problem. Most organisations are well-staffed for the first and almost entirely unprepared for the second. Anthropic's decision to launch a dedicated enterprise AI services company — backed by Blackstone, Goldman Sachs, and major PE firms — signals exactly this gap. The organisations winning with AI in 2026 are not necessarily the ones with the most advanced models. They are the ones with the operational infrastructure to keep those models healthy, compliant, and improving over time.
What Is an AI Agent, Really?
Before building anything, it is worth being precise about what an AI agent actually is — because the term is overloaded to the point of uselessness in most vendor marketing.
AI agent definition: An AI agent is a system that perceives input from its environment, uses a large language model to reason about what action to take next, executes that action through tools or APIs, observes the result, and repeats this loop until a goal is achieved or a stopping condition is met. It is distinguished from a chatbot by its ability to take multi-step actions, and from a workflow automation by its use of LLM reasoning — rather than predefined logic — to decide what to do next.
A chatbot waits for a question and answers it. A workflow automation executes a fixed sequence of predefined steps. An AI agent decides, at each step, what action to take next based on its current context, goal, and the results of previous actions. This distinction matters enormously for both architecture and operations: agents are inherently harder to predict, test, and monitor than either chatbots or automations.
The five components of every AI agent
Every production AI agent system is built from five components. Understanding each one — and the failure modes specific to each — is the prerequisite for building agents that work beyond the demo.
1. The reasoning engine (LLM). The model that reads the agent's current state and decides what to do next. The choice of model — GPT-4o, Claude 3.7 Sonnet, Gemini 2.0, Llama 3 — affects capability, latency, cost, and compliance posture. For most production applications, a frontier model handles complex reasoning while a smaller, faster model handles simple subtasks. This tiered routing typically cuts LLM costs by 30–50 percent compared with routing everything through a single frontier model.
2. Memory. AI agents have two types. Short-term memory is the active context window — everything the agent can "see" during a single reasoning step. Long-term memory is an external store (vector database, relational database, key-value cache) that the agent can query across multiple sessions or steps. Memory architecture is one of the most consequential design decisions you make — get it wrong and you will either run out of context budget or miss information the agent needs to reason correctly.
3. Tools. Functions the agent can call to interact with the world: web search, database queries, code execution, REST API calls, email send, file read and write. The quality of your tool definitions — specifically the natural-language descriptions that tell the LLM when and how to call each tool — is often the single biggest determinant of agent performance in production. Vague tool descriptions cause the LLM to call the wrong tool, pass wrong parameters, or hallucinate successful tool calls that failed silently.
4. Orchestration. The logic that sequences the agent's reasoning loop: how goals decompose into sub-tasks, how multiple agents hand off to each other, how stopping conditions are defined, and how errors in tool calls are handled. Your choice of framework determines how much of this you configure versus build from scratch.
5. Observability. Structured logging of every reasoning step, every tool call and its result, every token consumed, and every error encountered. Most teams add this last. It should be added first. Without observability, you cannot diagnose production failures, detect drift, optimise costs, or satisfy a compliance audit. We return to this repeatedly throughout this guide because it separates agents you can operate from agents you can only hope are working.
The 5-Layer Stack You Need Before Writing a Line of Code
The most expensive mistake in AI agent projects is opening a code editor before making infrastructure decisions. The five decisions below determine whether your agent can scale, stay within cost budgets, and survive a compliance review. Make them before writing any agent logic.
Layer 1: LLM selection and routing strategy
Select at minimum two models: a capable frontier model for complex reasoning and a cheaper, faster model for simple subtasks. A common production configuration uses Claude 3.7 Sonnet or GPT-4o for multi-step planning and tool selection, and Claude Haiku or GPT-4o Mini for classification, extraction, or summarisation steps. This tiered routing approach cuts inference costs dramatically without meaningful quality loss on simpler tasks.
Model selection also determines your compliance posture. If your agents process PHI, PII, or regulated financial data, the model provider's data processing agreement matters as much as the model's benchmark scores. Azure OpenAI and Anthropic's enterprise tier both offer dedicated deployments with stronger data isolation than their standard API tiers — a requirement for many regulated industry deployments.
Layer 2: Orchestration framework
The framework determines how you define agent roles, sequence tasks, manage state, and handle errors. The three frameworks that dominate production deployments in 2026 are CrewAI, LangGraph, and AutoGen — each with a distinct philosophy suited to different problem shapes. Full framework comparison in the next section.
Layer 3: Tool layer design
Before writing agent code, inventory every external system your agent will call. For each tool: define the function signature, write the natural-language description the LLM will use to decide when to call it, implement error handling and retry behaviour for the most likely failure cases, and test in isolation before connecting to the agent. Poor tool definitions are the most common upstream cause of agent hallucinations and incorrect behaviour in production.
Layer 4: Memory and state architecture
Decide explicitly what your agent needs to remember and for how long. Short-term memory (the context window) has a hard token budget — everything passed to the model in a single call costs money and has a maximum size. Long-term memory (a vector store or database) has retrieval latency and accuracy tradeoffs that need to be measured at your data scale before going live. For agents that handle multiple sessions or long-running tasks, you also need state persistence — what gets saved between steps, where it lives, and how it is retrieved on resume.
Layer 5: Observability infrastructure
Configure structured logging before the first agent call runs in development. Minimum viable observability: a unique trace ID for every agent run, per-step logging of the LLM's input and output, tool call logging with full inputs and outputs, token consumption and cost per call, latency per step, and a structured error log. Tools like LangSmith, Weights & Biases, Helicone, or Arize Phoenix provide purpose-built dashboards. Without this infrastructure, you have no visibility into production failures and no data for optimisation sprints.
Choosing Your AI Agent Framework: CrewAI, LangGraph, AutoGen, or Custom
Framework selection is one of the highest-leverage decisions in an AI agent project. It shapes development velocity, production debuggability, and the complexity of ongoing operations. Here is an honest assessment of the three frameworks that matter in 2026, followed by a decision guide for choosing between them.
CrewAI: role-based agent collaboration
CrewAI organises agents as a crew — each agent has a defined role, goal, and backstory. Tasks are assigned to agents and the framework handles sequencing (sequential or hierarchical process). It is the fastest path from idea to working multi-agent system for use cases that fit the role-based model: research pipelines, content production workflows, data analysis crews, and multi-step automation sequences.
CrewAI's strengths are readability and development speed. You define agents in plain English and the framework handles orchestration. Its limitations emerge in production: less fine-grained control over state management, less natural fit for complex branching logic, and higher abstraction that makes root cause analysis harder when something fails inside the crew. For teams hiring CrewAI developers, production experience matters as much as prototyping speed — the framework behaves differently under real-world load and edge cases.
LangGraph: graph-based state machines
LangGraph models agent workflows as directed graphs — nodes are actions, edges are conditional transitions, and state flows through the graph. This gives you explicit, auditable control over every state transition. It is the preferred choice for complex workflows where correctness matters more than development speed: regulated use cases, multi-step workflows with complex branching, and systems where you need to reason precisely about what the agent can and cannot do at any given point.
LangGraph's strengths are control, testability, and debuggability. Every possible agent state is explicit in the graph definition. Individual nodes can be tested in isolation. Any production failure traces back to exactly which node and transition caused it. Its limitation is development overhead — LangGraph requires more upfront design and is more verbose than CrewAI. LangGraph engineers are rarer than CrewAI engineers partly because of this higher technical bar, which makes senior production experience especially valuable.
AutoGen: conversational multi-agent systems
AutoGen, from Microsoft Research, builds agents as conversational participants that communicate through structured dialogue and dynamically decide how to collaborate. It is best suited for exploratory workflows where the interaction pattern is not fully known in advance, and for organisations deeply integrated with the Microsoft stack (Azure OpenAI, Teams, Copilot Studio).
AutoGen's flexibility is its strength and its production challenge. Conversational agent systems are harder to constrain, test systematically, and cost-optimise than structured-flow frameworks. Production AutoGen deployments typically require more guardrailing to prevent runaway conversation costs and off-script behaviour.
| Dimension | CrewAI | LangGraph | AutoGen |
|---|---|---|---|
| Best for | Role-based workflows, fast delivery | Complex branching, regulated use cases | Exploratory, conversational, Microsoft stack |
| Development speed | Fast | Medium | Fast |
| Production control | Medium | High | Low |
| Debuggability | Medium | High | Low |
| Cost predictability | Good | Good | Variable |
| Compliance fit | Medium | High | Medium |
When to build a custom orchestration layer
Sometimes none of the three frameworks are the right answer. Consider a custom orchestration layer when your workflow does not fit the role-based or graph-based mental models, you have very specific state management requirements the frameworks do not support, or you need minimal latency overhead for a high-throughput production system. Custom builds are less common in 2026 than they were two years ago — the frameworks have matured significantly — but remain the right answer for genuinely unusual problem shapes.
Step-by-Step: Building Your First Production AI Agent
This section walks through the build process in sequence, with the decisions you need to make and the most common mistakes at each step.
Step 1: Write the goal, scope, and stopping conditions in plain English
Before writing code, write a one-paragraph description of: what the agent is trying to achieve, what inputs it receives, what actions it is allowed to take, and what success looks like. This document becomes your ground truth for testing and your specification for the system prompt. If you cannot write this clearly, the agent will not run clearly. Vague goal definitions are the most upstream cause of production failure — they propagate into vague system prompts, vague tool definitions, and agents that hallucinate solutions to problems that were never precisely specified.
Step 2: Define and test every tool in isolation
Write and test every tool function before connecting it to the agent. Each tool needs: a function that executes the action (API call, database query, code execution), a natural-language description the LLM will use to decide when to call it, explicit error handling for the most likely failure modes (rate limits, timeouts, empty results, malformed responses), and a unit test that verifies it works correctly in isolation. Tool definitions that are vague or inaccurate — the most common mistake — cause the LLM to call the wrong tool, pass wrong parameters, or confidently act on a failed tool call as if it succeeded.
Step 3: Write and version-control the system prompt
The system prompt is the agent's persistent instruction set. It defines the role, task framing, output format requirements, behavioural constraints, and edge case handling. Good system prompts are explicit, specific, and short enough that the LLM does not lose track of early instructions. Common mistakes: too long (the LLM loses track of early instructions in long prompts), too vague (the LLM fills gaps with unreliable assumptions), and not version-controlled (when the prompt changes, you do not know what changed or why performance shifted).
Treat prompts as code. Every change should be tracked in version control with: the version number, the date, the reason for the change, and a comparison of performance before and after. Without this discipline, you cannot distinguish model drift from prompt regression when performance degrades.
Step 4: Build the reasoning loop and run adversarial tests
Wire up the reasoning loop using your framework. Before touching production data, test with adversarial inputs: edge cases your agent might encounter in the wild (empty API results, ambiguous instructions, malformed inputs), inputs designed to confuse tool selection, and inputs that test your stopping conditions. The goal is to surface failures in testing, not production. Most AI agent projects skip adversarial testing entirely and discover their edge cases through user complaints.
Step 5: Add observability before connecting to production data
Before your agent touches any real data, instrument it with structured logging. This is the step that most teams skip and all teams regret. Minimum viable observability: a unique trace ID per run, per-step recording of the LLM's input and output, tool call logging with inputs and results, token count and cost per call, latency per step, and a structured error log with full context. Configure this before day one — retrofitting observability into a running production system is significantly harder than installing it at build time.
Step 6: Staged rollout with a human-in-the-loop checkpoint
Do not go from zero to 100 percent production traffic on launch day. Start with shadow mode (the agent runs in parallel with the human process, its outputs observed but not acted on), then a small percentage of real traffic with human review, then incremental increases as confidence grows. Install a human-in-the-loop checkpoint for outputs below a defined confidence threshold. This approach gives you real-world data on failure rates before those failures have consequences, and builds the stakeholder trust needed to justify higher autonomy levels over time.
The 6 Ways AI Agents Fail in Production
Understanding production failure modes before they occur is the difference between building agents that survive contact with real-world data and building agents that degrade silently. These are the six most common causes of AI agent failure in production, in rough order of frequency.
1. Model drift
The world changes. The model's training data does not. Over time, the gap between what the model was trained on and what it encounters in production widens — and performance degrades. For agents with RAG components, retrieval index staleness compounds this: the documents the agent retrieves become progressively more out of date relative to the real world the agent is supposed to reason about.
Model drift rarely causes a visible error. It makes the agent progressively worse at its job until users stop trusting it — at which point the degradation has typically been happening for weeks. Detecting drift requires baselining performance metrics at launch and monitoring them continuously thereafter. For a deep-dive on detection and remediation, see our guide on AI model drift in production.
2. Token cost spirals
AI agent token costs compound in ways that surprise teams whose cost estimates came from controlled testing. Production agents handle more concurrent users, longer conversation histories, larger retrieved document sets, and more complex multi-step reasoning than test environments. Common culprits: context window bloat (passing full conversation history into every call without truncation), inefficient RAG retrieval (fetching 10 documents when 2 would have been sufficient), no model tiering (routing simple subtasks through expensive frontier models), and no caching for deterministic subtasks. A per-query cost that seemed reasonable in testing becomes a budget crisis at production scale.
3. Tool failure and silent error propagation
In production, APIs rate-limit, databases time out, authentication tokens expire, and third-party services go down. Agents without explicit tool failure handling will crash, loop indefinitely, or — most dangerously — continue reasoning as if a failed tool call succeeded. Every tool needs three things: retry logic with exponential backoff for transient failures, a clear failure signal to the LLM when a tool cannot complete, and a defined fallback path when the tool is unavailable. Agents that do not have all three will eventually encounter a tool failure in production and handle it badly.
4. Context window overflow
Every LLM has a maximum context window. Agents that accumulate conversation history, retrieve large document sets, or run long multi-step tasks can hit this limit mid-execution. The result is either a hard API error or, worse, silent truncation where the model processes only part of the context and produces output based on incomplete information. Production agents need explicit context management: windowing strategies that preserve the most relevant history, retrieval systems calibrated to return the minimum sufficient document set, and monitoring that alerts when context usage approaches the limit.
5. Hallucination under adversarial or out-of-distribution inputs
Agents hallucinate. The question is not whether but when and at what rate. In production, you will encounter inputs the agent was not tested against, users who probe the system with unexpected requests, and edge cases that expose reasoning gaps. Hallucination rate should be treated as a first-class production metric: measured continuously against a golden evaluation dataset, tracked over time, and triggering investigation when it rises above the baseline. Output validation and guardrails — checking the agent's response before it is acted on — are essential for any agent that produces real-world consequences.
6. Data pipeline rot
For RAG-based agents, the vector database is a dependency that degrades without active maintenance. Documents go out of date. The embedding model used at indexing time may no longer match the model used at query time after an update. New documents that should be indexed are not. Connectors feeding the index fail silently. A RAG agent that was accurate at launch becomes an agent that confidently answers from stale data six months later. Data pipeline maintenance is not a one-time setup task — it is an ongoing operations discipline. The full maintenance playbook is in our guide on production RAG pipelines.
Kovil AI · AI Operations
Your agents are live. Now what keeps them from degrading?
Kovil AI monitors your production AI agents continuously — detecting model drift, cutting token costs by 20–35%, keeping RAG pipelines fresh, and producing monthly compliance reports. The operational discipline that most teams skip. Starting at $2,000/month with a 2-week risk-free trial.
What AI Operations Is — and Why It Is Not Optional
AI Operations is the discipline of keeping AI systems healthy after deployment. Think of it as the DevOps of AI: just as no serious engineering team ships software without CI/CD, monitoring, alerting, and incident response, no production AI team should ship agents without the infrastructure to detect failures, measure performance, and improve over time.
The reason AI Operations matters more than most teams expect: AI systems do not fail like traditional software. A traditional software bug produces a visible error. An AI agent degrading due to model drift or retrieval staleness continues producing outputs — just progressively worse ones. The system looks working from the outside while its quality erodes internally. By the time users report problems, degradation has typically been happening for weeks or months.
The three pillars of AI Operations
Monitor. Continuous measurement of the metrics that tell you whether your agent is performing as intended: accuracy against a golden evaluation dataset, hallucination rate, tool call success rate, token cost per interaction, latency percentiles (P50, P95, P99), retrieval relevance scores, and error rates. Monitoring without baselines is noise — establish your metrics at launch so you know what "good" looks like and can detect deviations.
Optimise. Monthly improvement sprints targeting metrics that have degraded or cost lines that have grown beyond budget. Targets typically include prompt engineering improvements, context window reduction (most production agents have substantial context bloat that can be reduced without quality loss), RAG retrieval tuning, model tiering to reduce inference costs, and caching layers for deterministic subtasks. A mature AI operations practice delivers 20–35 percent token cost reduction within the first 90 days as a baseline expectation.
Govern. Structured audit logging, output guardrails, PII detection and masking, compliance reporting for regulated industries, and human-in-the-loop checkpoints for high-stakes decisions. Governance requirements that are skipped at build time become expensive retrofits when compliance teams or enterprise customers require them. For regulated industries — healthcare, legal, financial services — governance is not a nice-to-have; it is a prerequisite for deployment. The full compliance logging guide is at AI compliance logging for regulated industries.
The key question for most engineering teams: build AI operations in-house or partner with a specialist? Building in-house is right when AI operations is a core business competency, you have dedicated engineering bandwidth, and your systems are complex enough to warrant custom tooling. For most mid-market teams, a managed AI operations partner is more cost-effective than the engineering overhead of building and maintaining the infrastructure internally — especially given the specialist knowledge required to operate LLM systems reliably.
LLMOps: The Engineering Discipline Behind Reliable AI Agents
LLMOps is the specialisation of MLOps for large language model systems. It covers the engineering practices that make LLM-based systems — including AI agents — reliable, cost-efficient, and improvable over time. If MLOps asks "how do we ship and operate machine learning models?", LLMOps asks "how do we ship and operate systems whose outputs are stochastic, whose failure modes are subtle, and whose costs scale with every token generated?"
Prompt versioning and change management
Prompts are code. Treat them as such. Every change to a production system prompt should be tracked in version control with: a version number, the date of change, the reason for the change, and a comparison of performance before and after deployment. Changes should go through a defined review process — not be applied directly in production by whoever has API access. Prompt regressions (well-intentioned changes that degrade performance) are a common and preventable cause of quality degradation in production AI agents. Without versioning, you cannot even detect them, let alone fix them.
Evaluation frameworks and golden datasets
You cannot improve what you cannot measure. Production AI agents need a continuous evaluation pipeline: a golden dataset of representative inputs and expected outputs, automatic scoring that runs against every new model or prompt version before it goes live, and a human review process for cases where automatic scoring is insufficient. Evaluation approaches that work in production: LLM-as-judge (using a frontier model to score another model's outputs against defined criteria), RAGAS for RAG-specific evaluation metrics (context precision, context recall, faithfulness), and custom domain rubrics for use cases where generic metrics miss what matters.
Token cost tracking at the step level
Token cost is a first-class engineering metric. Track it at the granularity of: total cost per agent run, cost breakdown by step (which steps consume disproportionate tokens and why), cost per user session, and trend over time. Cost spikes are often the first visible signal of a configuration problem — a prompt that grew without review, a retrieval system that started fetching more documents, a conversation history that is being passed without truncation. Configure automated alerts on cost anomalies. Catching a 40 percent cost spike on day one of a configuration regression is far cheaper than discovering it on the monthly invoice.
Model version pinning and upgrade management
Model providers update their models continuously. Some updates are minor improvements; others change model behaviour in ways that affect agent performance — positively or negatively. Never point a production agent at "latest." Pin to a specific model version. Before upgrading: run the new version against your golden evaluation dataset, compare against acceptance criteria, plan the upgrade during low-traffic hours, and monitor closely for 48 hours after the change. Teams that ignore model version management regularly encounter performance regressions whose root cause is a model update they did not notice.
Production Architecture: What Separates Agent Demos from Real Systems
The architectural patterns below are what distinguish AI agents that work reliably at production scale from demos that impressed in a controlled test environment. Each pattern addresses a failure mode that does not appear in development but becomes a real problem under production conditions.
Async execution with job queuing
Many AI agent tasks are long-running — a research agent that takes two minutes to complete, a document processing agent handling a batch of files, a data analysis agent making twenty sequential tool calls. Synchronous execution of long-running tasks blocks resources, fails on network timeouts, and creates a bad user experience when the connection drops mid-task. Production agents should use async execution with a job queue (Celery, BullMQ, AWS SQS, or equivalent): the task is submitted and given a job ID, processed asynchronously in a worker, and the client polls or subscribes to a completion notification. This pattern makes agents resilient to network interruptions and enables horizontal scaling.
Idempotent tool calls and retry safety
Networks fail. Agents crash mid-task. In production, you need to safely retry any step in the reasoning loop without producing duplicate side effects. This means designing tool calls to be idempotent: calling the same tool with the same inputs twice should produce the same result without creating duplicate database records, sending duplicate emails, or triggering duplicate financial transactions. Idempotency keys — unique identifiers included with each tool call — are the standard mechanism. The receiving system uses the key to detect and deduplicate retries. Without this, agent retries become a source of data corruption.
State persistence and task resumability
Long-running agent tasks must be able to pause and resume. A task that fails at step 7 of 20 should not restart from step 1 — it should resume from step 7 with completed steps' outputs available as context. This requires explicit state persistence: after every completed step, the agent's current state (goal, completed actions, results, remaining work) is saved to a persistent store. State persistence also enables human-in-the-loop review of partially completed tasks and forensic analysis of failures without relying on in-memory traces that disappear when the process ends.
Rate limiting and circuit breakers for external tools
Production agents call external APIs that have rate limits and SLAs that will be violated. Implement exponential backoff with jitter for transient rate limit errors, circuit breakers that stop calling a tool after repeated failures (preventing cascading failure where one unavailable tool causes the entire agent run to fail), and queue-based rate limit management for high-throughput agents. Agents that do not handle rate limits and external service failures gracefully will produce hard-to-diagnose failures in production — the failures often do not look like tool errors but like agent reasoning failures.
Output validation before any consequential action
Before an agent's output is acted on — before an email is sent, a database is written, a financial transaction is triggered — validate it against expected format and content constraints. Output validation catches malformed JSON before it crashes downstream systems, detects PII in outputs that should not contain it, flags responses that trigger content policy guardrails, and ensures output structure matches what downstream consumers expect. Validation adds a few milliseconds of latency and prevents a class of production failures that are disproportionately expensive to remediate after the fact.
Kovil AI · Build AI Agents
Need engineers who have shipped production AI agents before?
Kovil AI's engineers have built production AI agent systems across CrewAI, LangGraph, and AutoGen — with async architecture, state persistence, observability, and guardrails included from day one. Matched in 48 hours, 2-week risk-free trial.
How Enterprise Teams Structure AI Agent Ownership
One of the most underappreciated decisions in AI agent deployment is organisational: who owns the agent after it is live? The answer determines whether the agent is maintained, optimised, and improved over time — or quietly degrades until it is decommissioned or replaced.
The handoff problem
In most organisations, AI agents are built by a specialist team (the AI team, a consulting partner, or an embedded engineering team) and then handed off to a product team, an operations team, or — most commonly — nobody in particular. The build team moves on to the next project. The receiving team does not have the LLMOps expertise to maintain the agent, interpret its monitoring data, or diagnose performance regressions. The agent runs on autopilot until it breaks visibly or becomes embarrassingly bad, at which point the build team is pulled back in for emergency repairs. This pattern is predictable, expensive, and preventable.
The three ownership models
Dedicated AI ops team. 2–4 engineers dedicated to AI operations across all deployed agents — monitoring, optimisation, incident response, compliance. This model is justified at organisations with six or more production AI systems across multiple business units. High investment, high operational quality, strong economies of scale across many systems.
Feature team ownership. Each product team that ships an AI agent owns its operation. Works in organisations with strong engineering culture and teams with genuine LLMOps expertise. Fails when feature teams are too busy shipping new features to maintain existing agents — the most common outcome. AI agent maintenance is regularly deprioritised against new development in product team backlogs.
Managed AI operations partner. An external specialist handles ongoing operations: monitoring, alerting, monthly optimisation sprints, compliance reporting, incident response. This is the right model for mid-market organisations that need production-grade AI operations without the headcount to build a dedicated internal team. Kovil AI's AI Operations service is built specifically for this scenario — starting at $2,000/month with a 2-week risk-free trial and a free onboarding audit.
What the Anthropic enterprise services announcement signals
Anthropic's decision to launch a dedicated enterprise AI services company — backed by major institutional capital — is a signal about the market, not just about Anthropic. The gap between frontier AI capability and mid-market organisational readiness to operate AI systems is real, measurable, and not closing as fast as the enthusiasm around AI suggests. The organisations that are compounding returns from AI in 2026 are the ones that have invested in the operational discipline — not just the initial build. The ones that haven't are watching their AI investments depreciate.
The 18-Point Production Go-Live Checklist
Before any AI agent goes to production, verify every item below. This is the minimum viable checklist; regulated industries and high-stakes use cases will require additional domain-specific verification steps.
Architecture and infrastructure
- ✅ All tool functions have unit tests covering success, failure, and edge cases
- ✅ Async execution and job queuing implemented for tasks over 5 seconds
- ✅ State persistence tested: agent resumes correctly after mid-task failure
- ✅ Rate limiting and exponential backoff implemented for all external API calls
- ✅ Context window budget monitored with alerting before limit is reached
Observability
- ✅ Structured logging active: trace IDs, per-step input/output, token counts, latency
- ✅ Cost monitoring dashboard live with baseline and alert thresholds configured
- ✅ Error alerting configured with on-call routing and escalation path
- ✅ Performance baseline recorded against golden evaluation dataset
Quality and safety
- ✅ System prompt version-controlled and pinned to specific version for production
- ✅ Output validation layer implemented and tested with malformed and adversarial outputs
- ✅ Guardrails configured for PII detection and content policy compliance
- ✅ Human-in-the-loop checkpoint defined for low-confidence or high-consequence outputs
- ✅ Adversarial input testing completed — known edge cases handled gracefully
Operations and compliance
- ✅ Model version pinned — production agent does not point to "latest"
- ✅ Audit log schema defined and logging active for all applicable compliance requirements
- ✅ Rollback plan documented — how to disable or revert the agent if production fails
- ✅ Staged rollout plan defined — shadow mode, percentage traffic, or feature flag gating
What Autonomous AI Agents Can and Cannot Do Today
The marketing around autonomous AI agents implies capabilities that are not yet reliably delivered in production at scale. Getting this calibration right matters: overpromising autonomous capability to stakeholders sets expectations the technology cannot meet, and the trust damage from that gap is worse than setting accurate expectations from the start.
Where autonomous AI agents deliver reliably today
Autonomous AI agents are reliably effective in 2026 for well-defined, bounded workflows where the goal is clear, the tools are stable, and the domain is specific. Research compilation and synthesis: agents that search, read, synthesise, and format research reports from a defined source set deliver consistent value at production scale. Data enrichment: agents that take a list of companies and populate a database with firmographic data from multiple APIs are deployed and production-proven at scale across many organisations. Document processing: agents that extract structured information from unstructured documents — invoices, contracts, clinical notes — operate with high accuracy in regulated industries. Bounded customer-facing workflows: support triage agents, lead qualification agents, and appointment scheduling agents all operate reliably when conversational scope is defined and the human handoff is well-designed.
Where autonomous AI agents still struggle
Agents struggle with open-ended goals where the definition of "done" is ambiguous. Multi-step workflows with long dependency chains — where an error at step 3 corrupts all subsequent steps — remain brittle without careful state design and rollback logic. Tasks requiring deep judgment in genuinely novel situations outside the distribution the agent was designed for. Any workflow where a mistaken action is irreversible and consequential. And multi-agent coordination at scale — the more agents interact in complex ways, the harder it is to predict and control emergent behaviour.
The autonomy spectrum: four levels
Rather than thinking of agents as autonomous or not, think of autonomy as a spectrum with defined levels:
Level 1 — Assisted: The agent suggests actions; a human approves every one before execution. No autonomous action.
Level 2 — Supervised autonomous: The agent executes autonomously within a defined scope. A human reviews outputs before any action with external consequences.
Level 3 — Monitored autonomous: The agent executes and acts autonomously. Humans monitor aggregate performance, are alerted on anomalies, and review edge cases.
Level 4 — Fully autonomous: The agent operates without human review. Reserved for low-stakes, high-reliability workflows where the cost of a mistake is low and the agent's track record justifies the trust level.
Most production AI agents in 2026 operate at Level 2 or Level 3. Level 4 is appropriate only for agents with extensive production track records in well-bounded domains. Starting at Level 1 or Level 2 and earning trust upward based on demonstrated performance is the right trajectory — not because the technology cannot do more, but because stakeholder trust and organisational readiness typically cannot move faster than demonstrated evidence justifies.
Kovil AI · Free AI Audit
Already have AI agents in production? Get a free health check.
We review your current AI stack in 30 minutes and identify your top 3 production health risks — drift, cost spirals, compliance gaps, or architecture problems. Free. No commitment. 48-hour turnaround on findings.
The Realistic Path: From Zero to Production-Grade AI Agents
The path from "we want to build AI agents" to "we have production AI agents that work reliably and improve every month" is a sequence of phases with distinct engineering challenges. Most organisations underinvest in Phase 2 and skip Phase 3 entirely — which is why most AI agent projects deliver less value than their initial business case projected.
Phase 1: Scoped prototype (2–4 weeks). Define a single, bounded use case with a clear goal and measurable success criteria. Choose your framework. Build the tool layer. Write and test the system prompt. Validate against a representative test set. Objective: prove the concept is technically viable and establish a performance baseline. Do not expand scope until this phase succeeds.
Phase 2: Production hardening (2–4 weeks). Add async execution, state persistence, error handling, context management, and full observability instrumentation. Complete the go-live checklist above. Deploy to a small percentage of production traffic. Objective: reach production with the right infrastructure in place from the start, not retrofitted later.
Phase 3: Operational maturity (ongoing). Monitor continuously against baselines. Run monthly optimisation sprints — prompt tuning, cost reduction, retrieval improvements. Maintain data pipelines and retrieval index freshness. Manage model version upgrades. Produce compliance reports for regulated industries. Evaluate and extend agent capabilities as trust is established. Objective: maintain quality, reduce costs, and build the performance track record that justifies expanding the agent's autonomy level and scope over time.
If your team is ready to build but needs experienced AI engineers, Kovil AI has LLM engineers, CrewAI specialists, and LangGraph engineers available within 48 hours — all with production experience, not just prototyping backgrounds. If you have agents already running and want an honest picture of their health, the free AI audit takes 30 minutes and gives you the three most important things to fix. Either way, the right time to invest in production-grade AI operations is before the first user complaint, not after.
Related Services
Frequently Asked Questions
What is the difference between an AI agent and a chatbot?
A chatbot responds to individual queries in a conversational interface — it receives a message and generates a reply. An AI agent perceives its environment, reasons about what action to take next, executes that action through tools or APIs, observes the result, and repeats this loop until a goal is achieved. The key distinction is autonomous multi-step action: an agent can search the web, query a database, send an email, write code, and chain these actions together in a sequence that a human did not explicitly script — a chatbot cannot. Agents are substantially more complex to build and operate than chatbots, which is why production operations disciplines like LLMOps matter far more for agentic systems.
Which AI agent framework should I use in 2026 — CrewAI, LangGraph, or AutoGen?
The right framework depends on your use case. CrewAI is best for role-based, multi-agent workflows where development speed matters and the workflow fits the role-task mental model — research pipelines, content workflows, data analysis crews. LangGraph is best for complex workflows with conditional branching, regulated use cases requiring auditability, or any situation where you need explicit control over every state transition. AutoGen is best for exploratory, conversational agent patterns and organisations deeply integrated with the Microsoft stack. If none of the three fit your problem shape, a custom orchestration layer may be the right answer — though this is increasingly rare as the frameworks have matured.
How long does it take to build a production AI agent?
A scoped prototype with a single, well-defined use case typically takes 2–4 weeks. Production hardening — adding async execution, state persistence, observability, error handling, and completing a go-live checklist — adds another 2–4 weeks. Total time from scoping to production deployment for a single agent: 4–8 weeks for a focused team with the right expertise. Multi-agent systems with complex orchestration, RAG components, or regulated industry compliance requirements typically take 8–16 weeks. Timeline is heavily determined by how clearly the goal and scope are defined before build begins.
What is AI Operations and does my team need it?
AI Operations is the discipline of keeping AI systems healthy after deployment: monitoring model performance, detecting drift, optimising token costs, maintaining data pipelines, and governing outputs for compliance. You need it if you have AI agents running in production — because AI systems degrade silently over time in ways that traditional monitoring does not catch. Model drift, retrieval index staleness, and context bloat accumulate gradually without triggering obvious errors. Most teams discover they needed AI Operations when users start complaining about degraded quality — by which point the degradation has typically been building for months. The right time to start is at launch.
How do I prevent my AI agents from hallucinating in production?
Hallucination cannot be fully eliminated, but its rate and consequences can be managed. Key practices: ground agent responses in retrieved documents via RAG and require source citation, implement structured output schemas that constrain the response format, build an evaluation framework that measures hallucination rate continuously against a golden dataset, deploy guardrails that validate outputs before they are acted on, and design human-in-the-loop checkpoints for high-stakes decisions. Treat hallucination rate as a first-class production metric with defined acceptable thresholds and automated alerting when the rate exceeds baseline. For regulated industries, combine these with formal audit logging of every inference.
How much does it cost to run AI agents in production?
Production AI agent costs have three components: LLM inference (typically $0.001–$0.05 per agent run depending on model, task complexity, and context window size), infrastructure (compute, storage, vector database, job queue), and operations (monitoring, optimisation, maintenance — either in-house engineering time or a managed service). LLM inference costs scale with query volume and task complexity; infrastructure costs are relatively predictable. The most common cost surprise is context window bloat — agents that accumulate conversation history or retrieve large document sets without truncation can cost 3–5x more than well-optimised equivalents. Expect to spend 20–40% of your initial inference cost estimate on optimisation in the first 90 days of production.
Kovil AI · AI Operations
Ready to build AI agents that work beyond the demo?
Most AI agent projects stall between the prototype and production — or degrade silently after launch. Kovil AI scopes, builds, deploys, and operates AI agent systems end-to-end. Working agents, not prototypes.