The AI Development Lifecycle: A Complete Guide for Business Leaders (2026)
Most AI projects fail not because of the technology, but because teams skip critical phases of the AI development lifecycle. Here is every stage explained, what goes wrong at each one, and how to run an AI project that actually ships.
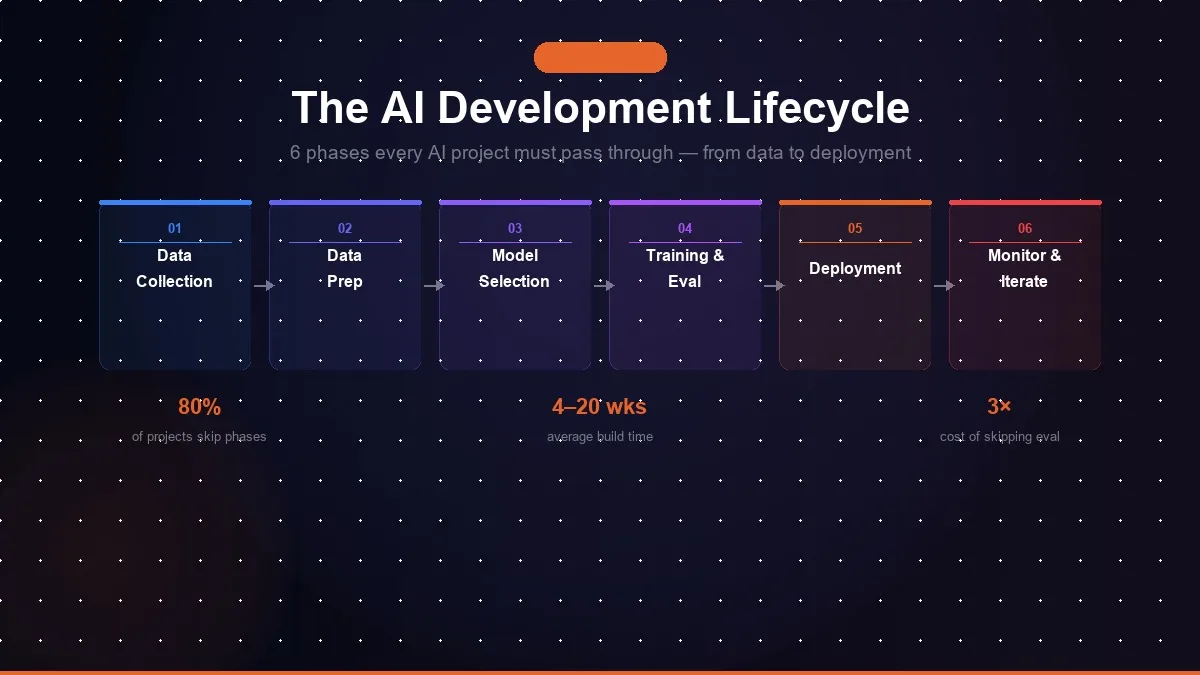
More than 80% of AI projects never reach production. That number has barely moved despite massive improvements in the underlying technology. The models are better. The tooling is better. The compute is cheaper. And yet most AI projects still fail.
The reason is almost never the technology. It is the process. Teams skip phases, rush past critical checkpoints, and discover fatal problems too late, after weeks or months of work. Understanding the AI development lifecycle is the single most important thing a business leader can do before committing to an AI project.
Kovil AI · AI Engineering
Our engineers guide AI projects from planning to production — step in at any stage.
Here is every phase explained plainly, what goes wrong at each one, and what a properly run AI project looks like in 2026.
What Is the AI Development Lifecycle?
The AI development lifecycle (AI SDLC) is the structured sequence of phases required to take an AI capability from idea to production, and keep it running reliably after deployment. It has six core phases:
- Problem definition and scoping
- Data collection and preparation
- Model selection and development
- Evaluation and testing
- Deployment
- Monitoring and iteration
These phases are not waterfall, real projects move between them iteratively. But each phase has its own set of decisions, artifacts, and failure modes. Skipping any of them introduces risk that compounds downstream.
Phase 1: Problem Definition and Scoping
This is the most important phase of the AI development lifecycle, and the one most frequently shortchanged.
Problem definition means translating a business need into a precise, technically solvable problem statement. It requires answering:
- What specific decision, task, or outcome is AI being asked to improve?
- What does success look like, quantitatively? What is the minimum acceptable performance threshold?
- What data exists to train or ground the system, and is it accessible?
- What are the consequences of the model being wrong, and how wrong is acceptable?
- How will the AI output be used, by a human reviewing it, or autonomously in a production workflow?
Teams that skip or rush this phase typically discover three weeks into development that they are solving the wrong problem, that their success metric cannot be measured, or that the data they assumed existed does not actually exist in usable form.
Common failure at this phase: Defining the problem as "build us a chatbot" or "add AI to our dashboard" without specifying what the chatbot should do, what data it should use, or what good performance looks like. For a detailed breakdown of what happens when this phase is skipped, see why 80% of AI projects fail in production.
Fintech example
A lending platform scoping an AI document reviewer defines success as: "Extract 12 specific data fields from mortgage applications with ≥98% accuracy, flagging low-confidence extractions for human review." That is a solvable problem. "Use AI to speed up document processing" is not.
Phase 2: Data Collection and Preparation
Most AI systems are only as good as the data they are built on. This phase covers sourcing, cleaning, transforming, and validating the data that the system will be trained on or grounded in.
For large language model (LLM) applications, which represent the majority of enterprise AI projects in 2026, data preparation typically means:
- Auditing existing documentation, databases, and knowledge sources for quality and coverage
- Cleaning, chunking, and structuring text for retrieval-augmented generation (RAG) pipelines
- Identifying and filling knowledge gaps
- Labelling examples for fine-tuning or evaluation datasets
For predictive models and classical ML, data preparation is more involved: handling missing values, feature engineering, managing class imbalance, and ensuring training data is representative of the real-world distribution the model will encounter in production.
Common failure at this phase: Training/production distribution mismatch, the model performs well on historical data used for development but encounters very different inputs in production. This is the most common reason why a model that looks good in testing disappoints in the real world.
Healthcare example
A hospital building an AI clinical note summariser discovers that 30% of notes are dictated (inconsistent formatting, filler words, abbreviations) vs typed. The RAG pipeline built on typed notes alone fails badly on dictated input. Data prep must account for both sources before model development starts.
Phase 3: Model Selection and Development
This phase involves choosing the right AI approach for the problem and building the core system. In 2026, this choice is usually not about training a model from scratch, it is about selecting the right foundation model and architecture for the task.
Key decisions in this phase include:
- Foundation model selection: GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro, Llama 3, or a specialised model? The right choice depends on performance benchmarks for your specific task type, cost per token at your expected query volume, latency requirements, and data privacy constraints.
- Architecture: Simple prompt engineering, RAG pipeline, fine-tuning, or a multi-agent system? Each has different complexity, cost, and maintenance profiles.
- Tool and integration design: For agentic systems, every tool the agent can call must be explicitly defined, tested, and bounded to prevent unintended actions.
- Workflow automation layer: Many AI systems require an automation backbone. If you are choosing between n8n, Power Automate, Zapier, or Make, see our 2026 automation tool comparison for a direct head-to-head breakdown.
Common failure at this phase: Over-engineering. Teams reach for complex multi-agent architectures or custom model training when a well-structured RAG pipeline with a strong foundation model would have solved the problem in a fraction of the time and cost.
SaaS example
A SaaS company building an AI support agent evaluates GPT-4o vs Claude 3.5 Sonnet on 500 real support tickets. Claude scores 4% higher on accuracy but costs 20% more per query at their volume. They choose Claude for tier-1 complex queries and GPT-4o mini for simple FAQs, a hybrid routing strategy that cuts inference cost by 35%.
Phase 4: Evaluation and Testing
This is the phase that separates teams who ship reliable AI from teams who ship demos. Evaluation means systematically measuring the system's performance, not just whether it works on the examples you thought of, but how it handles the full range of real-world inputs it will encounter.
A rigorous evaluation process for an LLM application includes:
- Accuracy benchmarks: Does the system give correct, grounded answers on a representative test set?
- Failure mode analysis: What kinds of inputs cause the system to fail, hallucinate, or behave unexpectedly?
- Adversarial testing: Can the system be manipulated by unusual inputs, prompt injection, or edge cases?
- Latency and throughput testing: Does performance hold at production query volumes?
- Human evaluation: For high-stakes outputs, does the system's output meet the standard that a domain expert would accept?
Common failure at this phase: Evaluating only on clean, well-formed examples that look like your development data. Production inputs are messier, more varied, and less cooperative than anything you imagined while building the system.
E-commerce example
An e-commerce platform testing an AI returns processor evaluates 1,000 clean return requests and hits 96% accuracy. Adversarial testing then reveals the system can be gamed by users who describe ineligible items using eligible item vocabulary. A validation layer is added before launch, catching a fraud vector the team never anticipated.
Phase 5: Deployment
Deployment is the transition from a working system in a controlled environment to a live system serving real users. In AI projects, deployment has unique considerations beyond standard software deployment.
Key deployment decisions include:
- Rollout strategy: Shadow mode (running the AI in parallel with the existing process), canary deployment (routing a small percentage of traffic to the AI system first), or full cutover?
- Human-in-the-loop design: Where does a human review AI outputs before they take effect, and where does the AI act autonomously? This decision has significant implications for risk, cost, and latency.
- Fallback handling: What happens when the AI system fails, returns a low-confidence result, or encounters an out-of-distribution input? A production AI system needs explicit degradation paths.
- Infrastructure and cost: LLM API costs, vector database hosting, compute for inference, these need to be modelled at expected production query volume before deployment, not after.
Common failure at this phase: Treating AI deployment the same as software deployment. A software system that works correctly keeps working correctly unless you change it. An AI system's performance can degrade over time without any code changes, because the world changes and the model's training distribution no longer matches reality.
Insurance example
An insurance firm deploys an AI claims triage system in shadow mode for three weeks, running it in parallel with human reviewers without acting on its outputs. Discrepancies are reviewed daily. Shadow mode reveals two systematic failure patterns before go-live, each of which would have caused compliance issues if caught post-deployment.
Phase 6: Monitoring and Iteration
The AI development lifecycle does not end at deployment. Production AI systems require ongoing monitoring to detect performance degradation, capture edge cases for future training, and adapt to changing business requirements.
A production monitoring setup for an AI system typically includes:
- Output quality sampling: Periodic human review of a random sample of the system's outputs to catch quality drift before it becomes a user-visible problem
- Input distribution monitoring: Alerting when the types of inputs the system receives shift significantly from its training distribution
- Latency and error rate dashboards: Standard infrastructure monitoring for uptime and performance
- User feedback integration: Capture of explicit or implicit signals when users are dissatisfied with AI outputs
Monitoring data feeds back into the next iteration of the lifecycle, new edge cases become evaluation test cases, persistent failure modes inform fine-tuning or RAG improvements, and shifting requirements trigger new scoping cycles.
Common failure at this phase: Treating deployment as the finish line. Teams that do not invest in monitoring often only discover that their AI system has degraded when a user or client reports a problem, by which point the damage is done.
Legal tech example
A legal research platform monitors its AI contract analyser monthly and detects a 7% accuracy drop six months post-launch. Root cause: a new contract template format from a major vendor is now common in the wild, and the system was never trained on it. Monthly output sampling catches this before any client notices, triggering a targeted fine-tuning cycle.
How the AI Lifecycle Differs from Traditional Software Development
If you have experience running software projects, the AI development lifecycle will feel both familiar and unsettling. Familiar because it has phases, checkpoints, and deliverables. Unsettling because the rules are different in ways that matter.
In traditional software development:
- Correctness is verifiable, you can test whether code does what it is supposed to do
- Behaviour is deterministic, the same input always produces the same output
- Deployment is a relatively stable end state, the software keeps working until you change it
In AI development:
- Performance is probabilistic, you can only estimate how well the system will perform on the distribution of real-world inputs
- Behaviour is not fully predictable, LLMs produce different outputs for the same input across runs
- Deployment is the beginning of a monitoring and maintenance cycle, not the end of the project
These differences have real implications for project timelines, team composition, success metrics, and how you structure contracts with AI vendors and service providers.
Tools Used at Each Phase of the AI Development Lifecycle
| Phase | Common Tools |
|---|---|
| 1. Problem Definition | Notion, Confluence, Miro (for scoping docs and system diagrams) |
| 2. Data Preparation | Python (pandas, spaCy), LlamaIndex, Unstructured.io, Label Studio |
| 3. Model Selection & Dev | OpenAI GPT-4o, Anthropic Claude 3.5, LangChain, LlamaIndex, Pinecone, Weaviate |
| 4. Evaluation & Testing | LangSmith, Braintrust, Ragas, custom eval suites in Python |
| 5. Deployment | Vercel, AWS Lambda, Docker, n8n / Make (workflow orchestration) |
| 6. Monitoring & Iteration | LangSmith, Datadog, Grafana, PostHog, custom logging pipelines |
Running an AI Project That Actually Ships
The teams that consistently ship AI in production share a few characteristics. They invest disproportionately in problem definition before writing any code. They treat data readiness as a prerequisite, not an assumption. They build evaluation infrastructure early and use it continuously. And they treat deployment as the beginning of a monitoring discipline, not the end of the project.
Kovil AI's Managed AI Engineer engagement is structured around this lifecycle. Our AI engineers have run this process across dozens of production deployments, in fintech, healthcare, SaaS, and professional services, and they bring a tested methodology to every project, not just technical skills.
If you are scoping an AI project and want a frank assessment of where the risk sits and what the realistic timeline looks like, get in touch. We will tell you exactly what we see, including if we think the project is not ready to start yet.
Related Services
Frequently Asked Questions
What is the AI development lifecycle?
The AI development lifecycle is the end-to-end process of taking an AI project from initial problem definition through to production deployment and ongoing monitoring. It covers six core phases: problem definition and scoping, data preparation, model selection and development, evaluation and testing, deployment, and monitoring and iteration. Unlike traditional software development, AI projects require explicit data and model validation steps that most software teams are not accustomed to.
How is the AI development lifecycle different from the software development lifecycle?
The software development lifecycle (SDLC) is largely deterministic, if you write the code correctly, it behaves predictably. The AI development lifecycle is probabilistic, the model's behaviour depends on the data it was trained or grounded on, and performance must be measured empirically rather than verified logically. This means AI projects require additional phases (data validation, model evaluation, bias testing) that have no equivalent in traditional software projects.
Why do most AI projects fail?
The most common failure modes are: (1) Poorly defined success criteria, teams build something without agreeing on what 'good enough' means before they start. (2) Data problems discovered late, bad data quality, insufficient volume, or training/production distribution mismatch found after weeks of development. (3) Skipping evaluation, shipping without rigorous testing of edge cases, failure modes, and real-world inputs. (4) No monitoring after deployment, models degrade over time as the real world changes, and teams only find out when something breaks in production.
How long does the AI development lifecycle take?
A focused first AI project, one clearly defined use case with clean, accessible data, typically takes 6 to 12 weeks from scoping to production. Simple workflow automations and chatbots grounded in existing documentation can go live in 2 to 4 weeks. Complex custom model development, multi-system integrations, or projects requiring large-scale data preparation can take 3 to 6 months. The single biggest time variable is data readiness.
What is the most important phase of the AI development lifecycle?
Problem definition and scoping. Every failure mode in AI development can be traced back to insufficient clarity at the start: unclear success criteria, an underspecified problem, or a gap between what the team thinks they are building and what the business actually needs. An experienced AI engineer spends disproportionate time in this phase precisely because getting it right eliminates the most common and costly failure modes downstream.
Kovil AI · AI Engineering
Need an experienced team to guide your AI project?
We've taken AI projects from whiteboard to production across every stage of the lifecycle. Whether you're planning, mid-build, or stuck — we can step in.