What Is AI Operations? The Complete Guide (2026)
AI Operations is the engineering discipline that keeps AI systems accurate, cost-efficient, and compliant after launch. Learn what it covers, why AI systems degrade without it, and how to decide between building it internally or using a managed service.
You have shipped an AI system. The demo impressed the board, the pilot results were solid, and your engineering team is proud of what they built. Three months later, the outputs are subtly worse. Costs are climbing without any change in user volume. A compliance question arrived from legal and nobody knows where the audit log is. This is not a failure of the build — it is a failure of operations, and it is the most common pattern in AI deployment today.
AI Operations is the engineering discipline that prevents this. It is what keeps AI systems accurate, cost-efficient, and compliant after they go live. This guide covers what AI Operations actually means, why it matters, what it includes, and how engineering teams can decide whether to build it internally or bring in a managed provider. If you want the full lifecycle context — from building AI agents through to operating them — see the complete guide to building AI agents that work in production.
Kovil AI · AI Operations
We operate production AI systems — monitoring, drift detection, cost optimisation, and compliance as a managed service.
What Is AI Operations?
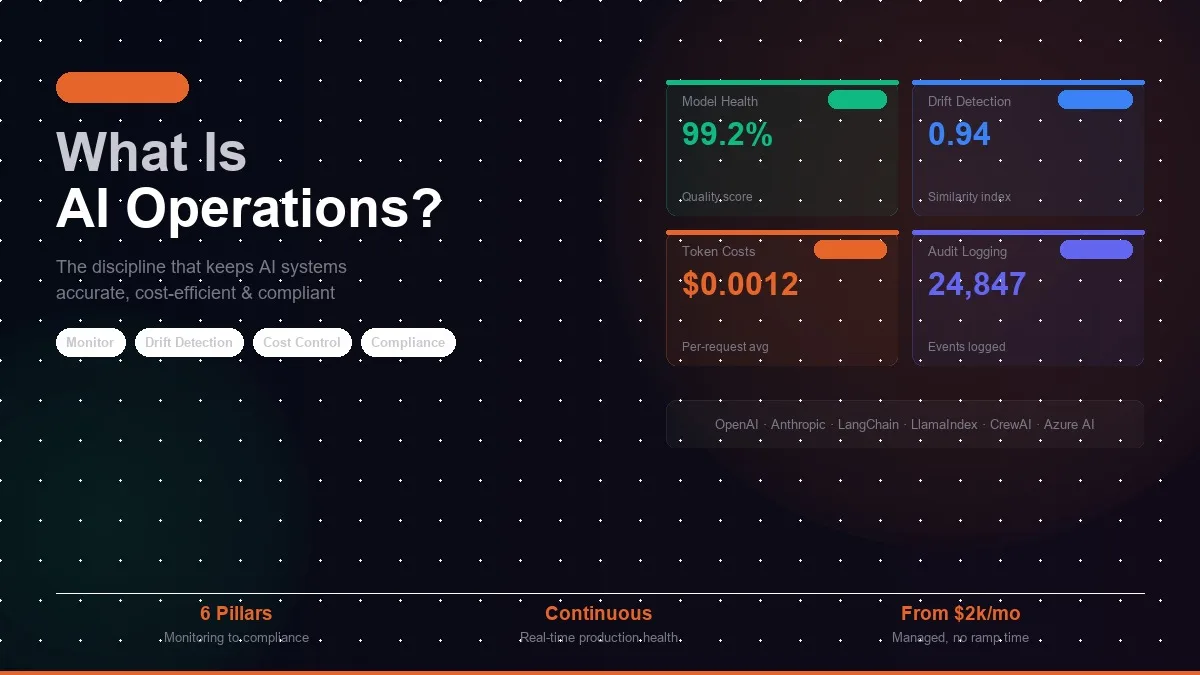
AI Operations (also called AI Ops, or LLMOps when focused on large language models) is the set of engineering practices, tooling, and processes required to keep AI systems healthy, performant, and compliant in production. It covers everything that happens after deployment: monitoring, drift detection, cost optimisation, data pipeline management, compliance logging, and incident response.
The term borrows from DevOps and MLOps but is distinct from both. DevOps handles software deployment pipelines and infrastructure reliability. MLOps handles the training, versioning, and deployment of machine learning models. AI Operations handles what happens to those systems once they are live and serving real users — specifically the unique failure modes of AI systems that do not exist in traditional software: output drift, hallucination rate changes, retrieval degradation, prompt template erosion, token cost spirals, and silent accuracy decline.
These failure modes share one defining characteristic: they are silent. There is no 500 error, no deployment pipeline failure, no alerting system firing. The AI system continues serving requests while those requests receive measurably worse answers. By the time users complain, weeks or months of degraded performance have already accumulated.
Why AI Systems Degrade Without Operations
Traditional software does not get worse on its own. A web application serving users in January will serve users identically in July, assuming no code changes. AI systems are fundamentally different. They degrade for reasons entirely disconnected from the application code:
- Data distribution shift — The real-world data the system processes changes over time. A customer support agent effective on 2024 ticket language starts struggling with queries using newer product terminology or evolved user phrasing patterns.
- Retrieval index staleness — RAG systems pull answers from document indexes that go stale as source materials change. Answers become outdated without any visible error signal — the system confidently retrieves and cites documents that no longer reflect current reality.
- Model version changes — Foundation model providers update their models on their own schedules. A prompt effective on one model snapshot may produce meaningfully different outputs on a newer version, with no change on your side.
- Prompt template drift — System prompts that were carefully calibrated at launch become less effective as use patterns evolve, edge cases accumulate, and the gap between what the prompt anticipates and what users actually ask grows wider.
- Token cost creep — Without active management, token consumption grows through prompt template expansion, conversation history accumulation, context window bloat, and model tier changes. A system costing $800/month at launch can reach $8,000/month within 18 months without any increase in user volume.
- Guardrail erosion — Adversarial users probe and iterate on jailbreaks. Guardrails effective at launch require maintenance as new attack vectors emerge.
Each of these failure modes is observable and preventable with proper instrumentation. Without it, engineering teams are flying blind — aware their AI system is running, not whether it is running well.
Kovil AI · AI Operations
Is your AI system silently degrading?
Most teams don't find out until a user complains. Kovil AI instruments production monitoring, drift detection, and cost dashboards in a 2-week onboarding — so you know before your users do.
The Six Pillars of AI Operations
A mature AI Operations function covers six distinct engineering domains. Organisations differ on which they prioritise based on risk profile, regulatory environment, and scale — but all six are necessary for any production AI system serving real users.
1. Model Performance Monitoring & Alerting
The foundation of AI Operations is continuous measurement. Every inference should be tracked: output quality, latency, error rate, and user feedback signals (explicit ratings, implicit signals like follow-up queries, escalations, and abandonment). Monitoring establishes the baseline against which drift is detected — without a baseline, there is no meaningful definition of "worse."
Effective AI monitoring goes beyond uptime checks. The system can be fully available and returning responses while those responses are significantly degraded. Key metrics to instrument from day one:
- Output quality scores — automated evaluation using LLM-as-judge or ground-truth comparison against a held-out evaluation set
- Hallucination rate — factual accuracy checks against retrieved context, tracking how often model outputs contradict or fabricate information
- Latency percentiles — p50, p95, and p99, not averages (averages hide the tail latency that affects real user experience)
- Token consumption per request — broken down by system prompt, retrieved context, conversation history, and completion
- Retrieval precision — for RAG systems, are the retrieved documents actually relevant to the query?
- User satisfaction signals — thumbs down ratings, support escalations, session abandonment after AI responses
Alerting should fire when any of these metrics crosses a defined threshold relative to the established baseline — not just when the system goes down.
2. Model Drift Detection & Remediation
Drift detection identifies when a model's output quality has shifted meaningfully from baseline. In traditional ML, drift detection tracks statistical changes in input data distributions. In LLM-based systems, the concern is subtler: output quality degradation driven by any of the causes described above, even when the code and infrastructure are unchanged.
A practical AI drift detection workflow:
- Establish a quality baseline during the first 2–4 weeks of production on a representative query sample
- Run automated weekly evaluations against new production queries using the same evaluation framework
- Compare current quality scores against baseline with statistical significance checks
- Alert when scores drop beyond a defined threshold — typically 5–10% degradation triggers investigation
- Diagnose root cause: data distribution shift, model version change, retrieval index staleness, or prompt template mismatch
- Remediate: re-index, update prompt templates, pin or migrate model version, adjust retrieval strategy
- Document the incident and update runbooks for future occurrences
Drift remediation is an operational skill. The first time a team encounters a drift event, diagnosis takes days. With practiced runbooks and instrumented systems, the same event resolves in hours. For a detailed technical treatment, see the cluster post on AI model drift detection and remediation.
3. Token Cost Optimisation
Token cost is the most directly controllable cost variable in an AI system — and the one most organisations ignore until the invoice arrives and the engineering team scrambles to explain the spike.
A system costing $800/month at launch can reach $8,000/month within 18 months through: prompt template growth (adding new instructions without removing old ones), conversation history accumulation (not truncating or summarising long sessions), context window bloat (retrieving more documents than necessary), and model upgrade decisions made without cost impact analysis. These changes happen gradually, making them invisible without deliberate tracking.
Token cost optimisation covers:
- Prompt compression — removing redundant instructions, consolidating overlapping directives, and compressing examples without quality loss
- Context window management — truncation strategies, conversation summarisation, and retrieval result pruning
- Model tier routing — directing simple subtasks (classification, extraction, reformatting) to smaller, cheaper models while reserving larger models for complex reasoning
- Semantic caching — caching inference results for semantically similar queries to avoid repeat LLM calls on common inputs
- Output length control — constraining verbose model outputs where concise answers are sufficient
Well-executed token cost optimisation typically reduces costs by 25–40% without measurable quality impact. For a detailed breakdown, see how to reduce AI token costs in production.
4. RAG Index & Data Pipeline Management
RAG systems — which represent the majority of production LLM deployments — rely on knowledge indexes that must be actively maintained. Source documents change, new information is added, outdated content becomes misleading. Without active pipeline management, a RAG system's knowledge base diverges from reality while the system continues confidently answering questions.
Data pipeline operations include: incremental re-indexing on defined schedules, embedding model version management (embedding models change and older embeddings can degrade in quality relative to new documents indexed with newer models), chunk strategy optimisation, and retrieval quality evaluation — measuring precision and recall against a known query set to detect retrieval degradation before it affects user-facing outputs.
For production RAG pipeline architecture and management, see the guide to production RAG pipeline management.
5. Compliance Audit Logging
Regulated industries and enterprise buyers increasingly require demonstrable AI governance. This means structured, tamper-evident logging of every model inference: input hash, output hash, model version, latency, token cost, user context, and any PII masking events. Logs must be queryable and retained per the applicable regulatory framework.
The absence of AI audit logs is increasingly a deal-breaker in enterprise sales and a compliance liability in regulated industries. Financial services firms need to demonstrate that AI-assisted decisions can be explained and audited. Healthcare organisations need evidence that PII did not enter LLM context without appropriate controls. Legal teams need to show that AI-generated outputs were reviewed appropriately before acting on them.
AI compliance logging is not optional for teams with enterprise customers or regulatory exposure. For implementation guidance, see AI compliance and audit logging for production systems.
6. Incident Response & SLA Management
AI systems fail in ways that require expertise specific to AI to triage. A spike in hallucination rate, a retrieval index corruption, an embedding model deprecation, a provider-side model behaviour change — these require different runbooks from standard software incidents. A database query timeout is diagnosed the same way every time. An AI output quality regression has a dozen possible root causes requiring structured investigation.
AI Operations incident response means defined runbooks for common failure patterns, clear escalation paths, SLA commitments for different severity levels (P1: system returning no useful outputs; P2: measurable quality degradation; P3: cost or performance anomaly), and post-incident reviews that improve future response time.
Kovil AI · Managed AI Operations
All six pillars. One managed service.
Kovil AI covers monitoring, drift detection, token cost optimisation, data pipeline management, compliance logging, and incident response — from $2,000/month with a 2-week risk-free trial.
AI Operations vs MLOps vs DevOps
These three disciplines are frequently conflated. They are related but address different problems at different layers of the AI system stack:
| Discipline | Focus | Key Activities | Who Needs It |
|---|---|---|---|
| DevOps | Software deployment & infrastructure | CI/CD pipelines, uptime, rollbacks, infra provisioning | Every software team |
| MLOps | ML model training & deployment | Feature pipelines, model training, versioning, A/B testing | Teams training custom models |
| AI Operations | LLM & AI system health in production | Output monitoring, drift, cost optimisation, compliance | Every team running AI in production |
An organisation running a fine-tuned model on their own infrastructure needs all three disciplines. An organisation using a managed LLM provider (OpenAI, Anthropic, Google) with a RAG pipeline needs DevOps and AI Operations, but minimal MLOps — since foundation model training is handled by the provider. For a detailed comparison, see LLMOps vs MLOps: what is the difference and which do you need?
When Does an Organisation Need AI Operations?
The moment an AI system is serving real users in production, AI Operations is needed. Not at scale. Not at a particular revenue threshold. From day one of live usage.
The common mistake is treating AI Operations as something to "add later once the system proves itself." This reasoning assumes the system will communicate when it starts failing. It will not. Output degradation is silent. Token cost growth is invisible without dashboards. Compliance gaps are discovered during audits — after the fact, when the cost of remediation is highest.
The intensity of AI Operations does scale with risk and volume:
- Low volume, low stakes (internal tools, under 100 users) — lightweight quality monitoring and monthly drift reviews are a reasonable starting point
- Medium volume, customer-facing (SaaS features, support automation, lead qualification) — weekly drift checks, token cost tracking, defined incident runbooks, and retrieval quality evaluation are the minimum viable operations setup
- High volume or regulated (enterprise software, financial services, healthcare, legal) — continuous monitoring, compliance audit logging with defined retention, SLA-backed incident response, monthly compliance reports, and regular evaluation against adversarial test suites are required
The right time to set up AI Operations is before something goes wrong — because the instrumentation you need to diagnose a problem is the same instrumentation you need to detect the problem in the first place.
What AI Operations Looks Like Week-to-Week
One of the most practical ways to understand AI Operations is through the rhythm of actual engineering work. A mature AI Operations function runs on three cadences:
Continuous (real-time monitoring)
- Inference logging — every request and response recorded with metadata (model version, latency, token count, user context)
- Latency and error rate alerting — immediate notification when system availability or response quality drops below threshold
- Cost dashboards — per-request and aggregate token spend visible in real time, with anomaly alerting
- Guardrail violation logging — every triggered guardrail recorded for pattern analysis
Weekly (drift and quality review)
- Quality evaluation run — a representative sample of production queries evaluated against baseline using the established evaluation framework
- Drift check — statistical comparison of current quality scores to the established baseline; root cause investigation if drift threshold is crossed
- Cost review — identification of cost anomalies, per-endpoint cost growth, and optimisation opportunities
- Retrieval precision check — for RAG systems, validation of index freshness and retrieval relevance against known queries
Monthly (improvement and compliance)
- Improvement sprint — one targeted improvement to latency, cost, or quality based on the week's operational data
- Compliance report — structured summary of audit log activity, model versions used, PII masking events, and guardrail activations for regulated industries
- Model version review — assessment of provider model updates and their impact on output quality
- Roadmap input — recommendations for AI capability improvements based on observed user patterns and operational data
This cadence is what allows AI systems to improve over time rather than degrade. Without it, organisations discover problems reactively — through user complaints, support tickets, or, in regulated industries, audit findings.
Build vs Buy: Internal AI Operations vs Managed Service
Engineering teams building their first AI Operations capability face a genuine build-vs-buy decision. The considerations differ from typical software tooling decisions because AI Operations expertise is scarce, the failure modes are non-obvious, and the ramp time to build internal competency is measured in months, not weeks.
Building an internal AI Operations function makes sense when:
- You have existing ML engineering or data engineering capacity that is underutilised and can be redirected
- Your AI systems process data that cannot be shared with a third party due to regulatory constraints
- Your scale justifies a dedicated internal team — typically organisations with 50+ AI-powered production features, or where AI is a core product differentiator
- You have a multi-year commitment to AI as infrastructure and can invest in building the competency internally
A managed AI Operations service makes sense when:
- Your engineering team's core value is building product, not maintaining AI infrastructure — and AI Operations is a tax on that capacity
- You want AI Operations capability without the 6–12 month ramp time to hire, train, and build tooling internally
- Your AI systems were built by a previous team (agency, contractor, prior hire) and institutional knowledge is limited
- You need compliance logging and audit trails but lack the infrastructure expertise to build tamper-evident systems
- You are in a cost-sensitive phase and need operations coverage without a full-time hire
Kovil AI's managed AI Operations service is structured for engineering teams in the second category: organisations that need production-grade AI Operations without the overhead of building and staffing an internal function from scratch. The service covers all six pillars, operates on a defined weekly cadence, and starts with a free 2-week onboarding audit regardless of which tier the engagement moves to.
Kovil AI · Get Started
Start with a free 2-week AI Operations audit
Every Kovil AI engagement begins with a full audit of your production AI system — architecture review, monitoring gaps, cost baseline, and compliance posture. No commitment required for the first two weeks.
Key Takeaways
- AI Operations is the discipline that keeps AI systems accurate, cost-efficient, and compliant after launch — it is not a product feature, it is an engineering function
- AI systems degrade silently — through data drift, retrieval staleness, model version changes, prompt erosion, and token cost growth — with no visible error signal
- The six pillars are: model performance monitoring, drift detection and remediation, token cost optimisation, RAG index and data pipeline management, compliance audit logging, and incident response
- AI Operations is distinct from MLOps (which covers model training) and DevOps (which covers software deployment and infrastructure)
- Every production AI system needs AI Operations from day one — the intensity scales with volume and risk, but the instrumentation requirement does not
- The build-vs-buy decision depends on internal engineering capacity, data sensitivity, scale, and how quickly the organisation needs the capability
For the full AI agent lifecycle — from framework selection through production deployment to long-term operations — read the pillar guide: How to Build AI Agents That Work in Production (2026).
Related Services
Frequently Asked Questions
What is AI Operations?
AI Operations (also called AI Ops or LLMOps) is the engineering discipline covering everything required to keep AI systems healthy after deployment: model performance monitoring, drift detection and remediation, token cost optimisation, data pipeline management, compliance audit logging, and incident response. It addresses the unique failure modes of AI systems — silent output degradation, retrieval staleness, model version changes — that do not exist in traditional software.
How is AI Operations different from MLOps?
MLOps covers the machine learning model development lifecycle: feature engineering, model training, experiment tracking, and model deployment. AI Operations covers what happens after deployment — keeping production AI systems accurate, cost-efficient, and compliant. Teams using managed LLM providers (OpenAI, Anthropic, Google) rather than training their own models need AI Operations but minimal MLOps, since foundation model training is handled by the provider.
When does a company need AI Operations?
From day one of production usage. AI systems degrade without operations for reasons disconnected from code changes — data distribution shift, retrieval index staleness, model version updates, and prompt template erosion. The intensity of AI Operations scales with risk and volume: low-stakes internal tools need lightweight monitoring and monthly reviews; customer-facing systems need weekly drift checks and cost tracking; regulated or high-volume deployments need continuous monitoring, SLA-backed incident response, and compliance audit logging.
What does AI model drift mean?
Model drift means an AI system produces worse outputs than it did at launch, even though the code and infrastructure are unchanged. Drift occurs because the data the system operates on changes (data distribution shift), the knowledge index goes stale (retrieval degradation), the underlying foundation model is updated by the provider, or the gap between the system prompt and real-world query patterns grows over time. Drift detection involves running regular automated evaluations against a quality baseline established at launch, and alerting when scores drop beyond a defined threshold.
How much does AI Operations cost?
Internal AI Operations requires dedicated engineering time: typically 0.5–1 FTE for a single production system at medium volume, scaling to 2–3 FTE for complex multi-system deployments. Managed AI Operations services like Kovil AI start at $2,000/month (Maintain tier: monitoring, alerting, and incident response), scaling to $8,000–$15,000/month (Operate tier: adds proactive optimisation, cost reduction, and data pipeline management) and $25,000–$50,000/month (Accelerate tier: dedicated engineering team, continuous evaluation, compliance reporting). The managed service typically pays back through token cost savings and reduced engineering time within the first 90 days.
Can Kovil AI operate an AI system that another team built?
Yes. Kovil AI operates AI systems regardless of who built them. The onboarding process begins with a 2-week audit that documents the current architecture, establishes baseline performance metrics, instruments monitoring, and configures alerting thresholds. Systems built on LangChain, LlamaIndex, CrewAI, OpenAI APIs, Anthropic Claude, Azure OpenAI, and custom fine-tuned models are all supported.
Kovil AI · AI Operations
Need someone to run your AI in production?
Kovil AI covers all six AI Operations pillars — monitoring, drift detection, token cost optimisation, data pipeline management, compliance logging, and incident response — from $2,000/month with a 2-week risk-free trial.